- Model with continuous covariates
- Model with categorical covariates
- Transforming categorical covariates
Objectives: learn how to implement a model for continuous and/or categorical covariates.
Projects: warfarin_covariate1_project, warfarin_covariate2_project, warfarin_covariate3_project, phenobarbital_project
See also: Complex parameter-covariate relationships and time-dependent covariates
Model with continuous covariates
- warfarin_covariate1_project (data = ‘warfarin_data.txt’, model = ‘lib:oral1_1cpt_TlagkaVCl.txt’)
The warfarin data contains 2 individual covariates: weight which is a continuous covariate and sex which is a categorical covariate with 2 categories (1=Male, 0=Female). We can ignore these columns if are sure not to use them, or declare them using respectively the reserved keywords COV (for continuous covariate) and CAT (for categorical covariate):
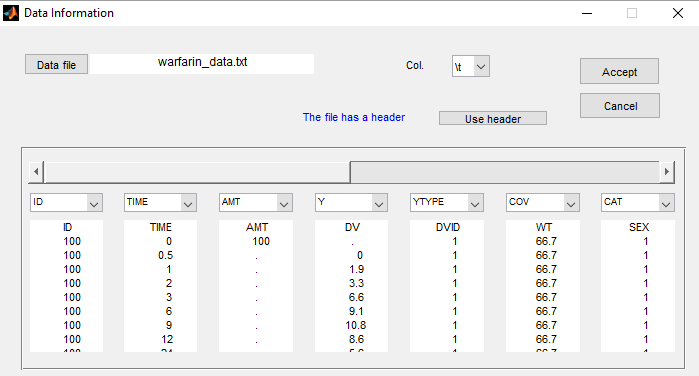
Even if these 2 covariates are now available, we can choose to define a model without any covariate:
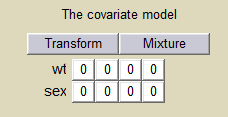
Here, a 0 on the first row (weight) and the third column (V), for instance, means that there is no relationship between weight and volume in the model. A diagnostic plot Covariates is generated which displays possible relationships between covariates and individual parameters (even if these covariates are not used in the model):
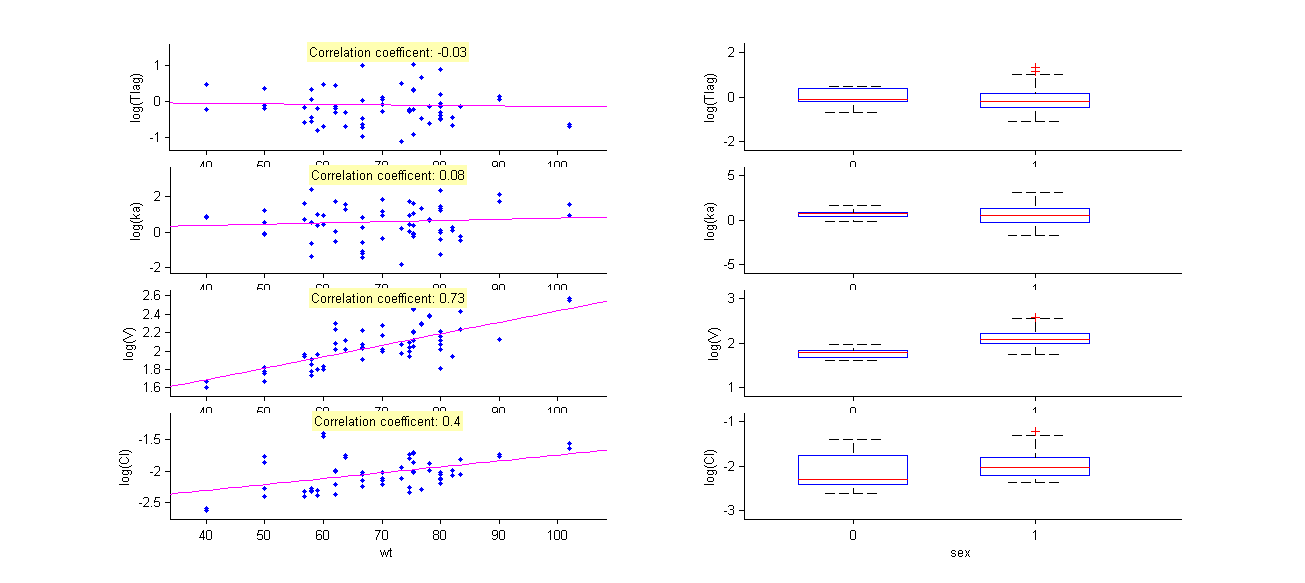
- warfarin_covariate2_project (data = ‘warfarin_data.txt’, model = ‘lib:oral1_1cpt_TlagkaVCl.txt’)
We decide to use the weight in this project in order to explain part of the variability of 

 &= \log(V_{\rm pop}) + \beta_V \, \log(w_i/70) + \eta_{V,i} \\\log(Cl_i) &= \log(Cl_{\rm pop}) + \beta_{Cl} \, \log(w_i/70) + \eta_{Cl,i} \\\end{aligned}")
which means that population parameters of the PK parameters are defined for a typical individual of the population with weight=70kg.
More details about the model
The model for
^{\beta_V} \, e^{ \eta_{V,i} } \\ Cl_i &= Cl_{\rm pop} ( w_i/70 )^{\beta_{Cl}} \, e^{ \eta_{Cl,i} } \end{aligned}")
The individual predicted values for
^{\beta_V} \\ \bar{Cl}_i &= Cl_{\rm pop} \left( w_i/70 \right)^{\beta_{Cl}} \end{aligned}")
and the statistical model describes how
 &\sim {\cal N}( \log(\bar{V}_i) , \omega^2_V) \\ \log(Cl_i) &\sim {\cal N}( \log(\bar{Cl}_i) , \omega^2_{Cl}) \end{aligned}")
Here, ")
")
")

Transform of the main GUI. We can then transform and rename the original covariates of the dataset:
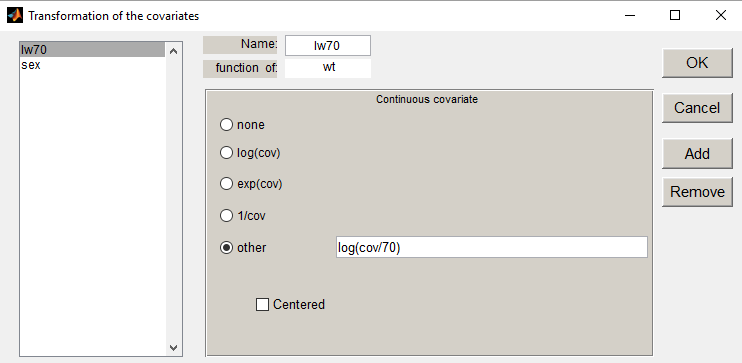
We then define a new covariate model, where 
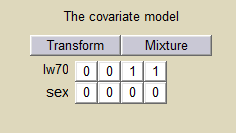
Coefficients 

Model with categorical covariates
- warfarin_covariate3_project (data = ‘warfarin_data.txt’, model = ‘lib:oral1_1cpt_TlagkaVCl.txt’)
We use sex instead of weight in this project, assuming different population values of volume and clearance for males and females.
More precisely, we consider the following model for
 &= \log(V_{\rm pop}) + \beta_V \, 1_{sex_i=F} + \eta_{V,i} \\\log(Cl_i) &= \log(Cl_{\rm pop}) + \beta_{Cl} \,1_{sex_i=F} + \eta_{Cl,i}\end{aligned}")
where 





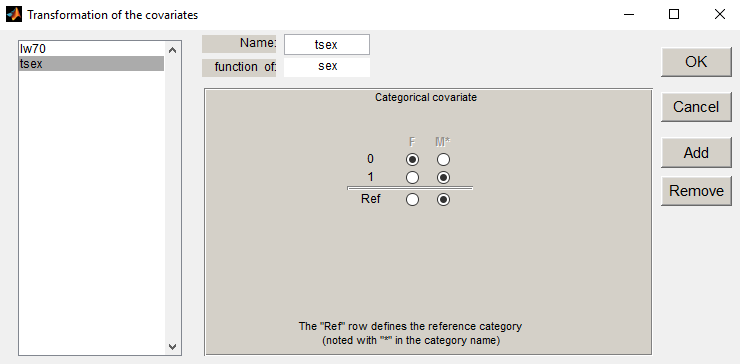
Transform, we can modify the name of the categories (click on the name of each category and enter a new name) and the reference category (Male is the reference category in this project):
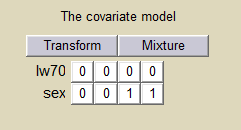
Define then the covariate model in the main GUI:
We can furthermore assume different variances of the random effects 
Cat. Var. and selecting which variances depend on the categorical covariate:
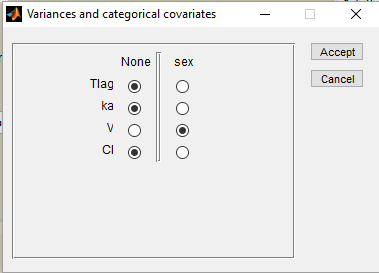
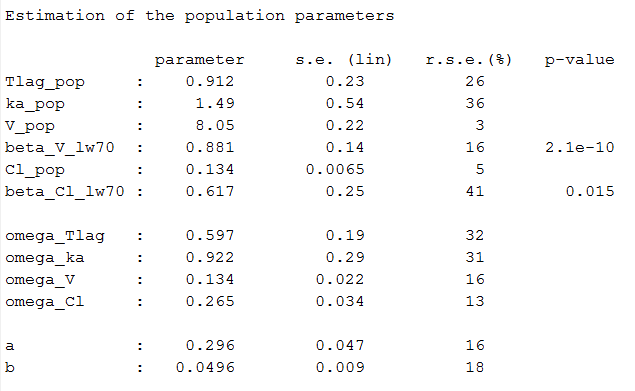
Estimated population parameters, including the coefficients 


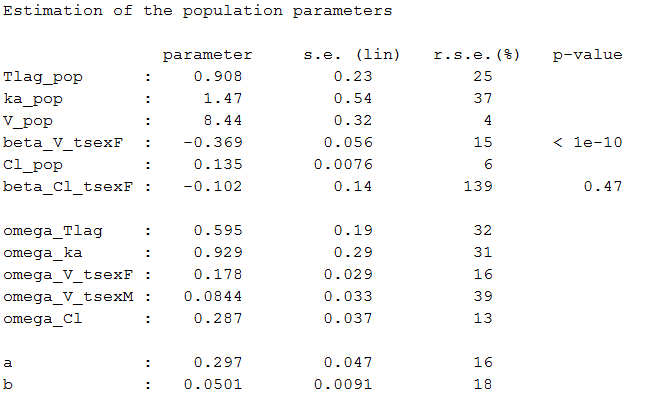
Estimated population parameters are also computed and displayed per category:

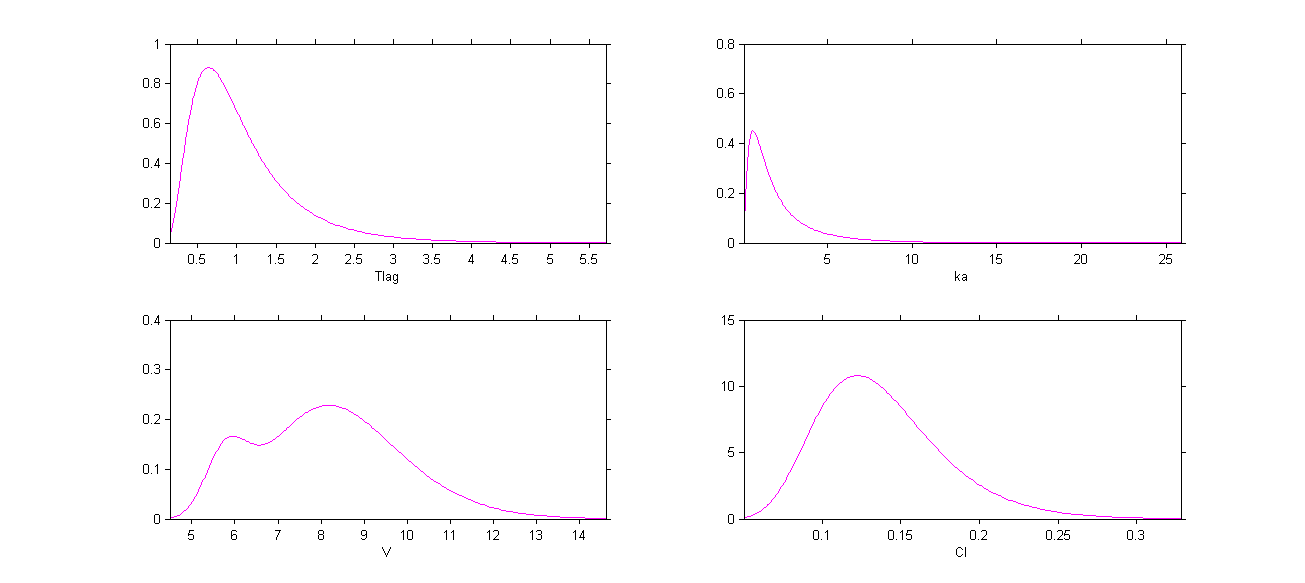
We can display the probability distribution functions of the 4 PK parameters:
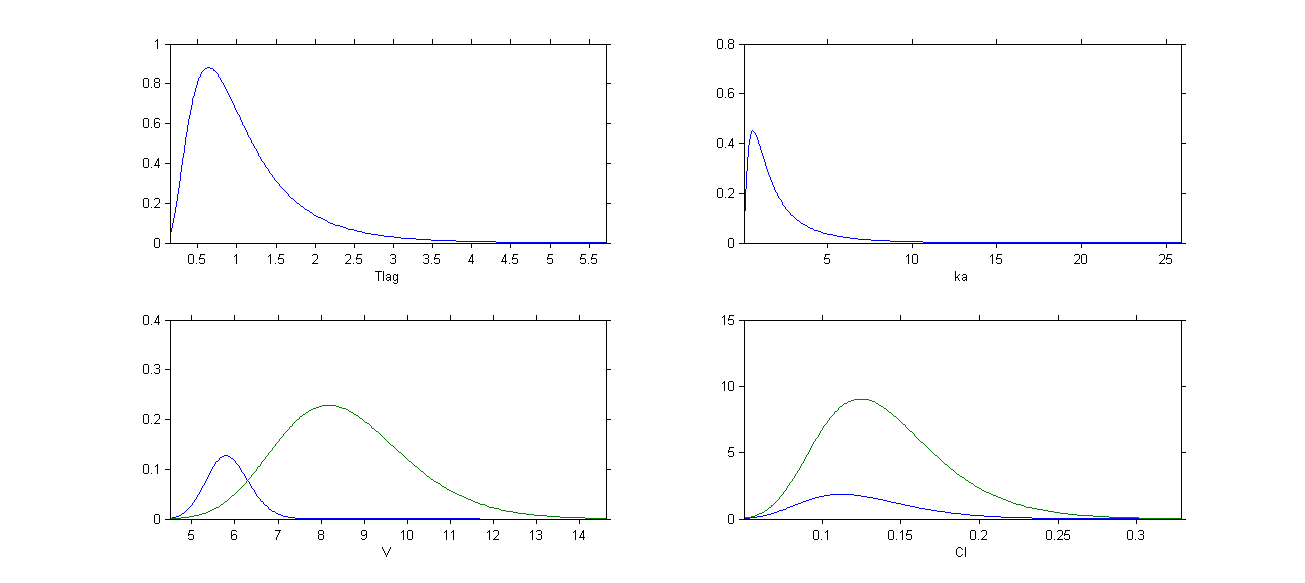
We can then distinguish the distributions for males and females by clicking on Settings and ticking the box By group:
Transforming categorical covariates
- phenobarbital_project (data = ‘phenobarbital_data.txt’, model = ‘lib:bolus_1cpt_Vk.txt’)
The phenobarbital data contains 2 covariates: the weight and the Apgar score which is considered as a categorical covariate:
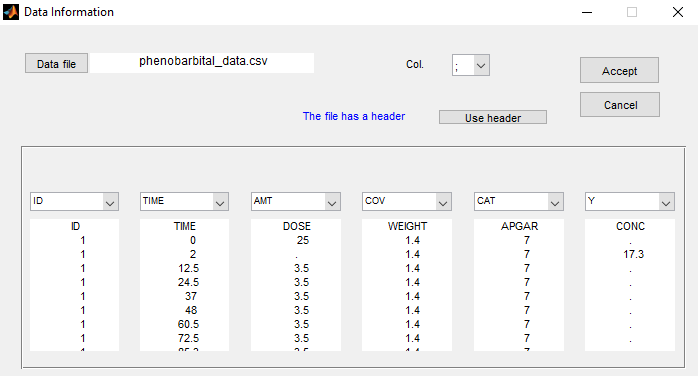
Instead of using the 10 original levels of the Apgar score, we will transform this categorical covariate and create 3 categories: Low = {1,2,3}, Medium = {4, 5, 6, 7} and High={8,9,10}.
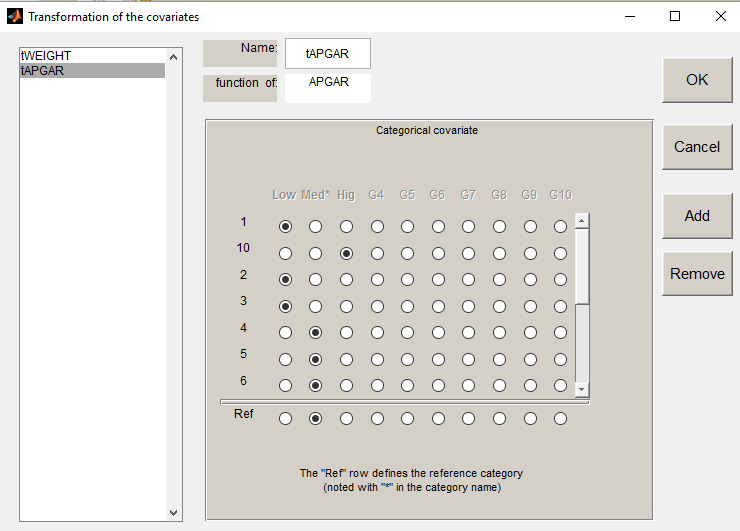
If we assume, for instance that the volume is related to the Apgar score, then 
