Objectives: learn how to define and use regression variables (time varying covariates).
Projects: reg1_project, reg2_project
Introduction
A regression variable is a variable 


")
 = x_j \quad \text{for} \ \ t_j \leq t < t_{j+1}")
Continuous regression variables
- reg1_project (data = reg1_data.txt , model=reg1_model.txt)
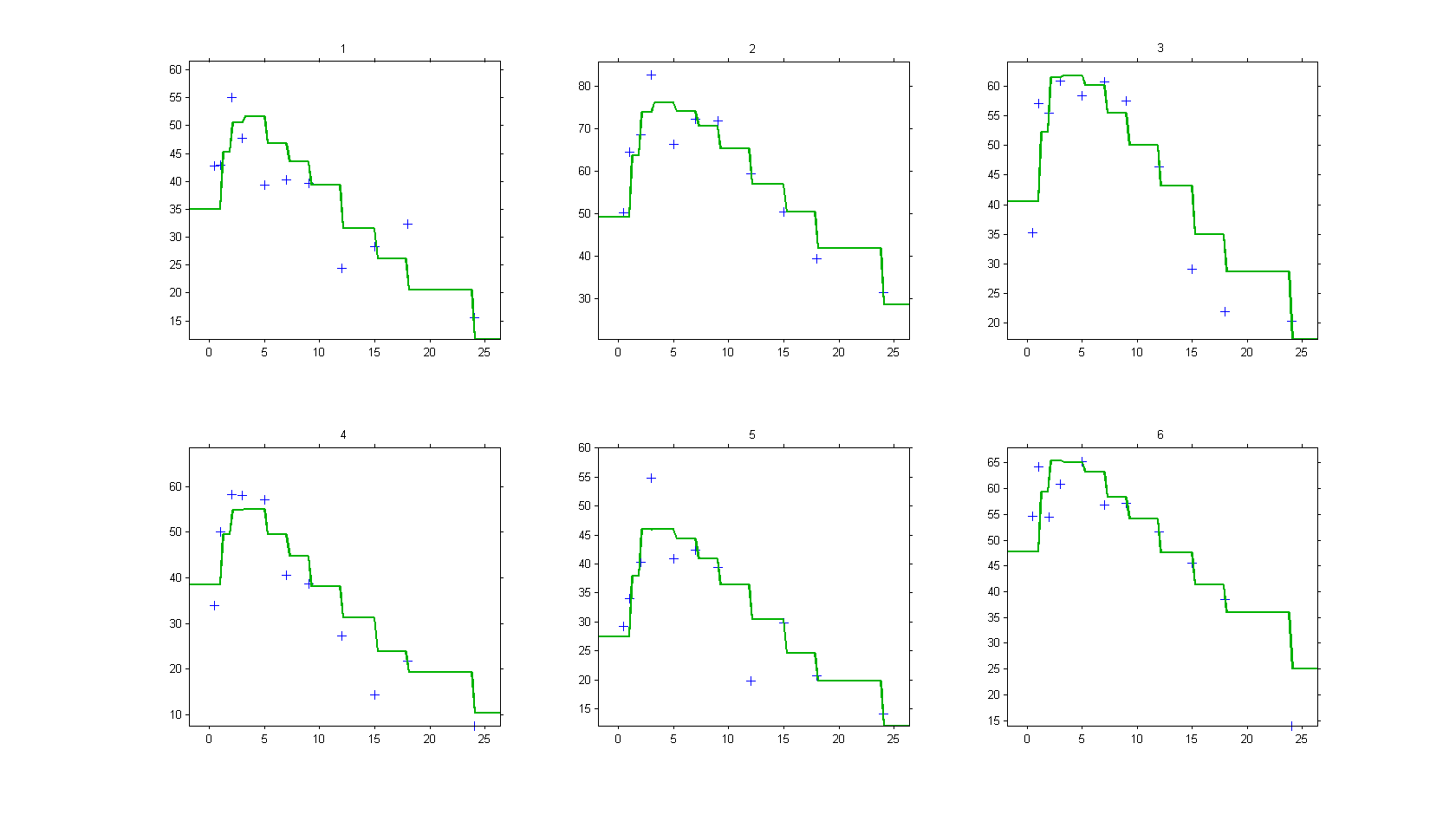
We consider a basic PD model in this example, where some concentration values are used as a regression variable:
[LONGITUDINAL]
input = {Emax, EC50, Cc}
Cc = {use=regressor}
EQUATION:
E = Emax*Cc/(EC50 + Cc)
The predicted effect is therefore piecewise constant: it changes at the time points where concentration values are provided:
Categorical regression variables
- reg2_project (data = reg2_data.txt , model=reg2_model.txt)
The variable 








[LONGITUDINAL]
input = {lambda1, lambda2, z}
z = {use=regressor}
EQUATION:
if z==0
lambda=lambda1
else
lambda=lambda2
end
DEFINITION:
y = {type=count, log(P(y=k)) = -lambda + k*log(lambda) - factln(k) }