- Introduction
- Count data with constant distribution over time
- Count data with time varying distribution
- Hidden Markov model for count data
Objectives: learn how to implement a model for count data.
Projects: count1a_project, count1a_project, count1a_project, count2_project, hmm0_project, hmm1_project
Introduction
Longitudinal count data is a special type of longitudinal data that can take only nonnegative integer values {0, 1, 2, …} that come from counting something, e.g., the number of seizures, hemorrhages or lesions in each given time period . In this context, data from individual j is the sequence ")


Count data models can also be used for modeling other types of data such as the number of trials required for completing a given task or the number of successes (or failures) during some exercise. Here, 
")


Count data with constant distribution over time
- count1a_project (data = ‘count1_data.txt’, model = ‘count_library/poisson_mlxt.txt’)
A Poisson model is used for fitting the data:
[LONGITUDINAL]
input = lambda
DEFINITION:
Y = { type = count, log(P(Y=k)) = -lambda + k*log(lambda) - factln(k) }
Residuals for noncontinuous data reduce to NPDE’s. We can compare the empirical distribution of the NPDE’s with the distribution of a standardized normal distribution:

VPC’s for count data compare the observed and predicted frequencies of the categorized data over time:
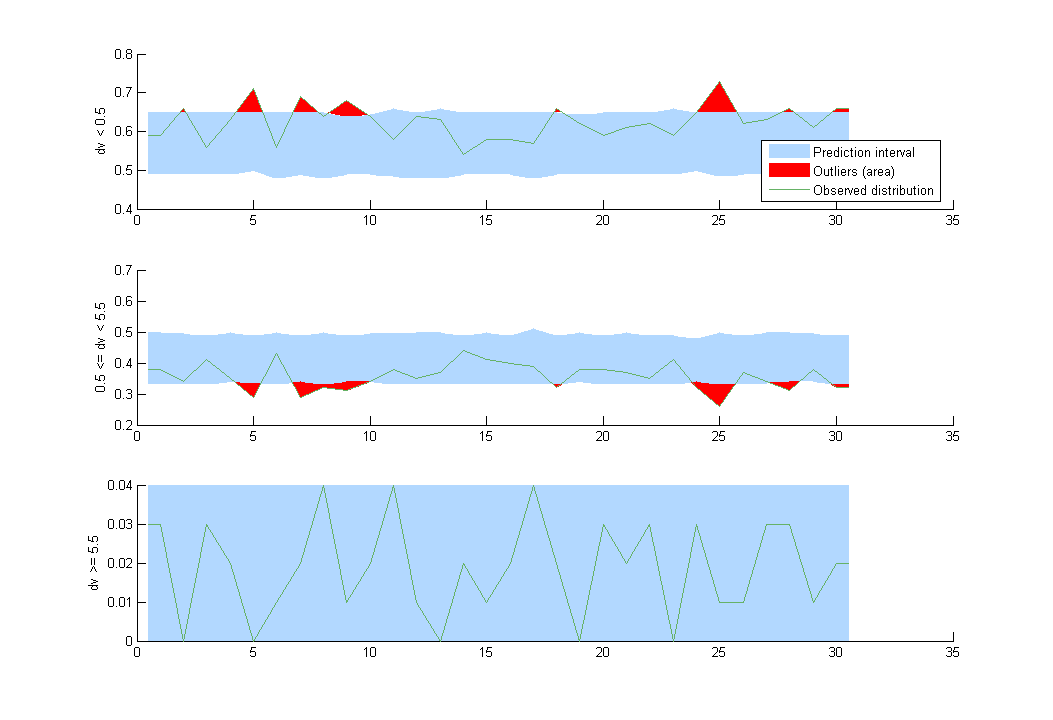
- count1b_project (data = ‘count1_data.txt’, model = ‘count_library/poissonMixture_mlxt.txt’)
A mixture of 2 Poisson distributions is used to fit the same data.
Count data with time varying distribution
- count2_project (data = ‘count2_data.txt’, model = ‘count_library/poissonTimeVarying_mlxt.txt’)
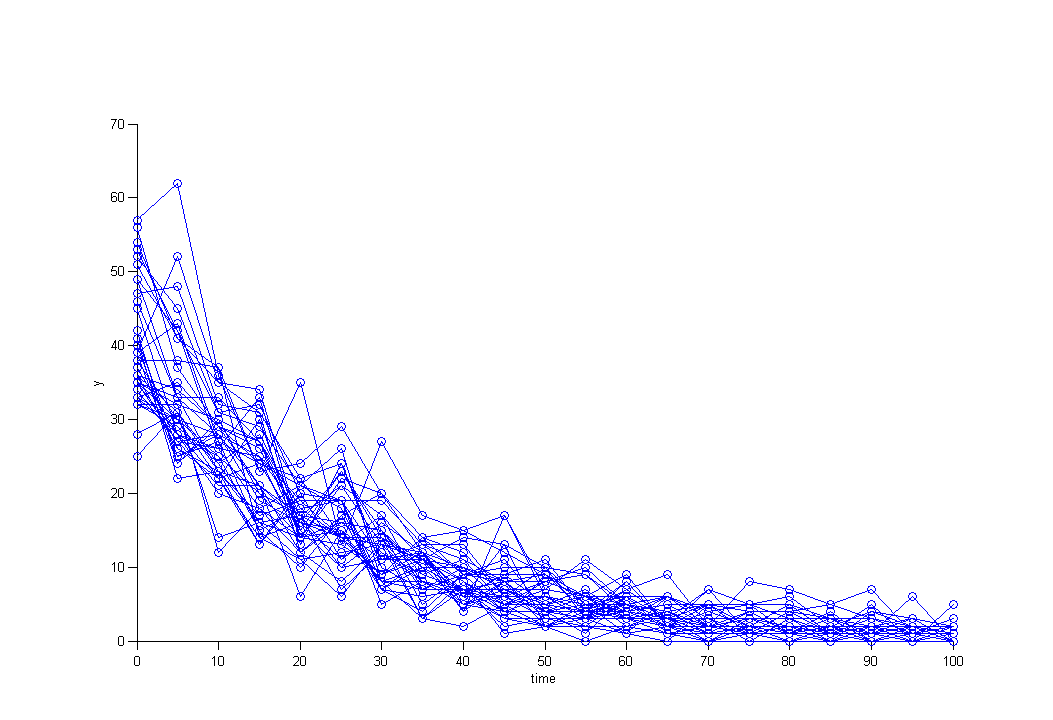
The distribution of the data changes with time in this example:
We then use a Poisson distribution with a time varying intensity:
[LONGITUDINAL]
input = {a,b}
EQUATION:
lambda= a*exp(-b*t)
DEFINITION:
y = {type=count, P(y=k)=exp(-lambda)*(lambda^k)/factorial(k)}
This model seems to fit the data very well:
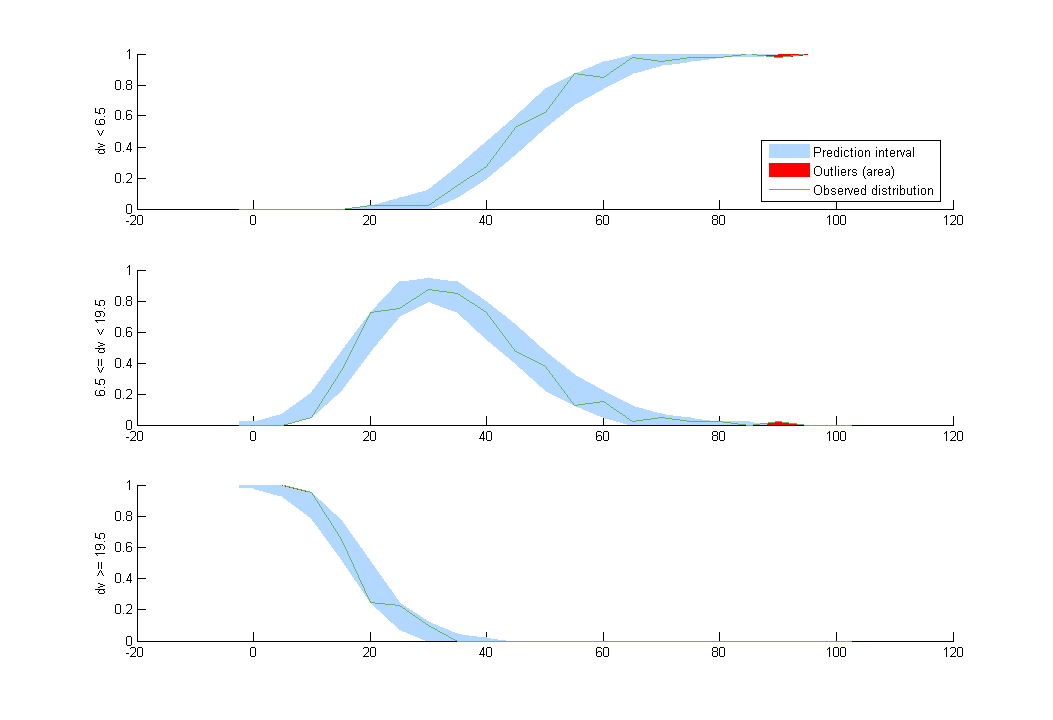
Hidden Markov model for count data
Markov chains are a useful tool for analyzing categorical longitudinal data. However, sometimes the Markov process cannot be directly observed and only some output, dependent on the (hidden) state, is seen. More precisely, we assume that the distribution of this observable output depends on the underlying hidden state. Such models are called hidden Markov models. An HMM is thus defined for individual 
")
")

In the following example, the latent sequence 




Remark: Models in the 2 following examples are implemented in Matlab (implementation with Mlxtran is not possible with the current version of Monolix). These models can be used with both the StandAlone and Matlab versions of Monolix, but they can only be modified with the Matlab version.
- hmm0_project (data = ‘hmm_data.txt’, model = ‘count_library/hmm0_mlx.m’)
The latent sequence
- hmm1_project (data = ‘hmm_data.txt’, model = ‘count_library/hmm1_mlx.m’)
The latent sequence